Недавно передо мной встала задача определения количества включенных компьютеров в нескольких подсетях нашей организации. Сеть ужасно запущена: нет ни домена, ни средств удаленной установки, поэтому поставить на все компьютеры агент мониторинга не было возможности. С другой стороны, на многих компьютерах был включен файрвол, из-за чего компьютеры не отвечали на ping-запрос.
Для решения этой задачи я использовал замечательную утилиту arping.
Arping работает на втором уровне модели OSI и не блокируется файрволом, т.к. компьютер должен отвечать на ARP-запросы, чтобы до него доходили IP-пакеты. Минусом arping по сравнению с ping является то, что arping работает в пределах одной локальной сети и не маршрутизируется. Однако это ограничение можно обойти с помощью проксирования ARP.
Для начала я написал простенький скрипт на PHP (это единственный язык, который я знаю ☺), использующий arping. Задаются сети и маски, и скрипт в цикле пингует каждый IP-адрес в них:
Но конечно, такой скрипт не годится для постоянного мониторинга. Во-первых, хотелось бы, чтобы он работал постоянно в фоновом режиме. Во-вторых, проверку нужно проводить в несколько потоков — так быстрее.
В итоге я переписал скрипт так:

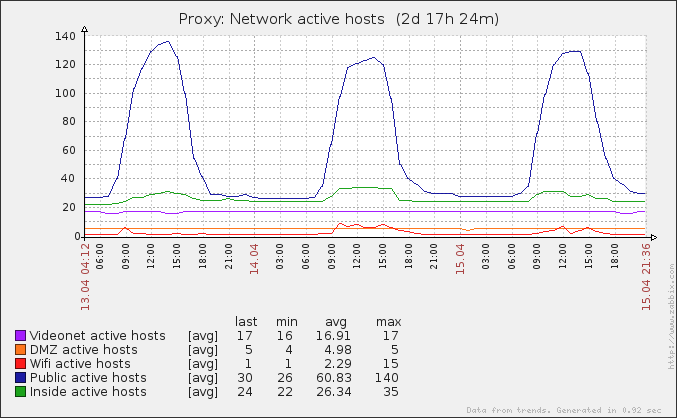
Также я добавил график в Zabbix (см. начало поста).
Для этого необходимо дописать в файл zabbix_agentd.conf строчку для каждой сети:
На сервере добавить соответствующие item'ы.

И настроить график.
Скрипт get_network_stats.php <имя_сети> выдает количество активных хостов по имени сети. Я думаю, пользователи других систем мониторинга смогут без труда прикрутить к ним этот скрипт.
Исходник приводить не буду, т.к. он большой. Скачайте его — readme прилагается.
Я думаю, кому нужна такая штука, может переписать его под свои нужды: например, можно использовать вместо memcached обычный файл.
Взято http://habrahabr.ru/blogs/sysadm/119112/
Для решения этой задачи я использовал замечательную утилиту arping.
Arping работает на втором уровне модели OSI и не блокируется файрволом, т.к. компьютер должен отвечать на ARP-запросы, чтобы до него доходили IP-пакеты. Минусом arping по сравнению с ping является то, что arping работает в пределах одной локальной сети и не маршрутизируется. Однако это ограничение можно обойти с помощью проксирования ARP.
Для начала я написал простенький скрипт на PHP (это единственный язык, который я знаю ☺), использующий arping. Задаются сети и маски, и скрипт в цикле пингует каждый IP-адрес в них:
//задаем сети и маски
$subnets = array("192.168.0.0/255.255.255.0", "10.10.8.0/255.255.252.0");
$up = 0; //количество живых хостов
foreach($subnets as $subnet)
{
list($addr, $mask) = explode('/', $subnet);
//вычисляем начальный и конечный адрес
$start = (ip2long($addr) & ip2long($mask)) + 1;
$end = $start + (~ ip2long($mask)) - 1;
//пробегаем все адреса и арпингуем их
for($ip = $start; $ip <= $end; $ip++)
{
$response = shell_exec("arping -c 2 " . long2ip($ip));
if(!strstr($response, '0 packets received')) $up++;
}
}
echo $up . "\r\n";
?>
Но конечно, такой скрипт не годится для постоянного мониторинга. Во-первых, хотелось бы, чтобы он работал постоянно в фоновом режиме. Во-вторых, проверку нужно проводить в несколько потоков — так быстрее.
В итоге я переписал скрипт так:
- Настройки и адреса сетей считываются из ini-файла.
- «Папа»-скрипт запускает экземпляр дочернего скрипта для каждой сети и контролирует его работу.
- Дочерний скрипт проверяет все адреса своей сети по кругу и обновляет информацию в Memcached. Помимо количества активных узлов запоминается их mac, dns и netbios имя.
- Из memcached эти данные можно посмотреть на веб-странице или в zabbix.
Также я добавил график в Zabbix (см. начало поста).
Для этого необходимо дописать в файл zabbix_agentd.conf строчку для каждой сети:
UserParameter=network_count.net_name,/usr/local/bin/php /путь до скрипта/get_network_stats.php net_nameНа сервере добавить соответствующие item'ы.
И настроить график.
Скрипт get_network_stats.php <имя_сети> выдает количество активных хостов по имени сети. Я думаю, пользователи других систем мониторинга смогут без труда прикрутить к ним этот скрипт.
Исходник приводить не буду, т.к. он большой. Скачайте его — readme прилагается.
Я думаю, кому нужна такая штука, может переписать его под свои нужды: например, можно использовать вместо memcached обычный файл.
Взято http://habrahabr.ru/blogs/sysadm/119112/
